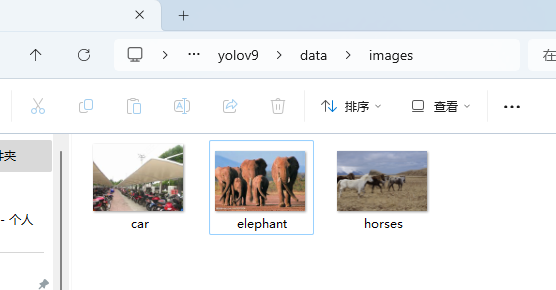
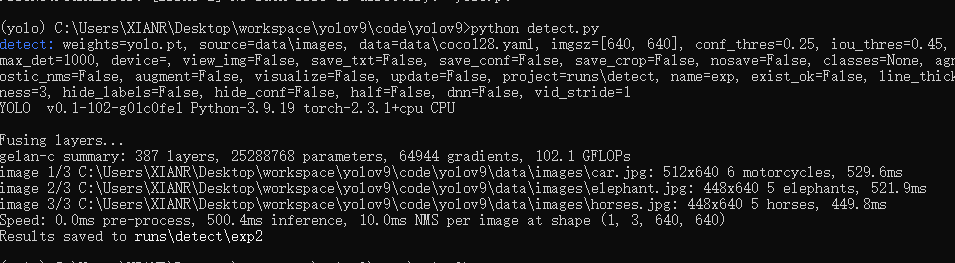
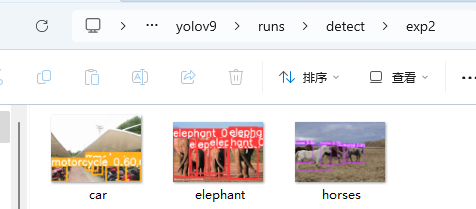
Hi 👋. Here is the homepage of Intelligent Cognitive Systems Laboratory (iCOST), Beijing University of Posts and Telecommunications.
Table of Contents
Introduction
The Intelligent Cognitive Systems Laboratory (iCost) at BUPT (Beijing University of Posts and Telecommunications) is actively engaged in long-term research in multiple cutting-edge fields, including computer vision and embodied intelligence. Our research spans various sub-domains such as action recognition, human pose prediction and estimation, uncertainty research, multimodal and audio-visual learning, audio-visual event detection, medical image segmentation, 3D object detection, adversarial strategies, embodied navigation, and robot grasping.
Our research team has achieved substantial results, publishing numerous high-quality research papers in internationally recognized and authoritative journals such as IEEE Transactions on Image Processing (IEEE TIP), IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT), and top-tier conferences like AAAI.
In the Intelligent Cognitive Systems Laboratory, we encourage communication and collaboration among team members, fostering a rigorous and harmonious academic atmosphere. We warmly welcome scholars, researchers, and students who are passionate about artificial intelligence and related fields to join us or collaborate. We believe that everyone with a curiosity for science can find their stage here.
Papers
2D Human Pose Estimation
[PR 2024] Kinematics Modeling Network for Video-based Human Pose Estimation [paper] [code]
[TIP 2022] Relation-Based Associative Joint Location for Human Pose Estimation in Videos [paper] [code]
[KBS 2024] DHRNet: A Dual-Path Hierarchical Relation Network for Multi-Person Pose Estimation [code]
[-] BiHRNet: A Binary high-resolution network for Human Pose Estimation [paper]
3D Human Pose Estimation
[AAAI 2024] Lifting by Image - Leveraging Image Cues for Accurate 3D Human Pose Estimation [paper]
3D Human Motion Prediction
[KBS 2024] April-GCN: Adjacency Position-velocity Relationship Interaction Learning GCN for Human motion prediction [paper]
[TNNLS 2023] Learning Constrained Dynamic Correlations in Spatiotemporal Graphs for Motion Prediction [paper] [code]
[TCSVT 2023] Collaborative Multi-Dynamic Pattern Modeling for Human Motion Prediction [paper]
[TCSVT 2022] Towards more realistic human motion prediction with attention to motion coordination [paper]
[TCSVT 2021] TrajectoryCNN: a new spatio-temporal feature learning network for human motion prediction [paper] [code]
[Neurocomputing 2024] Physics-constrained Attack against Convolution-based Human Motion Prediction [paper] [code]
[Neurocomputing 2022] Temporal consistency two-stream CNN for human motion prediction [paper]
[机器人 2022] 面向人体动作预测的对称残差网络 [paper]
[MPE 2020] A Hierarchical Static-Dynamic Encoder-Decoder Structure for 3D Human Motion Prediction with Residual CNNs [paper] [code]
[Cognitive Computation and Systems 2020] Stacked residual blocks based encoder–decoder framework for human motion prediction[code]
[-]Uncertainty-aware Human Motion Prediction [paper]
[-] MSSL: Multi-scale Semi-decoupled Spatiotemporal Learning for 3D human motion prediction [paper][code]
[-] DeepSSM: Deep State-Space Model for 3D Human Motion Prediction [paper] [code]
Early Action Prediction
[TIP 2024] Rich Action-semantic Consistent Knowledge for Early Action Prediction [paper] [code]
[ICCSIP 2022] A discussion of data sampling strategies for early action prediction [paper]
[中国自动化大会 2023] An end-to-end multi-scale network for action prediction in videos
Skeleton-based Human Action Recognition
[TCSVT 2024] SiT-MLP: A Simple MLP with Point-wise Topology Feature Learning for Skeleton-based Action Recognition [paper] [code]
[RAS 2020] DWnet: Deep-wide network for 3D action recognition [paper] [code]
[-] Spatial-Temporal Decoupling Contrastive Learning for Skeleton-based Human Action Recognition [paper] [code]
Group Activity Recognition
[KBS 2024] MLP-AIR: An effective MLP-based module for actor interaction relation learning in group activity recognition [paper]
Uncertainty-aware Scene Understanding with Point Clouds
[TGRS 2023] Neighborhood Spatial Aggregation MC Dropout for Efficient Uncertainty-aware Semantic Segmentation in Point Clouds [paper] [code]
[TCSVT 2023] Instance-incremental Scene Graph Generation from Real-world Point Clouds via Normalizing Flows [paper] [code]
[TIM 2020] Multigranularity Semantic Labeling of Point Clouds for the Measurement of the Rail Tanker Component With Structure Modeling [paper] [code]
[ICRA 2021] Neighborhood Spatial Aggregation based Efficient Uncertainty Estimation for Point Cloud Semantic Segmentation [paper] [code]
[Tsinghua Science and Technology 2023] Dynamic Scene Graph Generation of Point Clouds with Structural Representation Learning [paper]
Audio Visual Learning
[TMM 2023] Leveraging the Video-level Semantic Consistency of Event for Audio-visual Event Localization [paper] [code]
[EMNLP 2023] Target-Aware Spatio-Temporal Reasoning via Answering Questions in Dynamic Audio-Visual Scenarios [paper] [code]
[计算机应用 2021] 基于关键帧筛选网络的视听联合动作识别 [paper]
[-] Past Future Motion Guided Network for Audio Visual Event Localization [paper]
Audio and Speech Processing
[ICPR 2024] Full-frequency dynamic convolution: a physical frequency-dependent convolution for sound event detection [paper] [code]
[Interspeech 2024] MFF-EINV2: Multi-scale Feature Fusion across Spectral-Spatial-Temporal Domains for Sound Event Localization and Detection [paper] [code]
Medical Image Segmentation
[IEEE-CYBER 2023] Multi-task Learning Network for CT Whole Heart Segmentation [paper]
[Biomedical Signal Processing and Control 2022] DC-net: Dual-Consistency Semi-Supervised Learning for 3D Left Atrium Segmentation from MRI [paper]
Adversarial Attack
[Neurocomputing 2023] Physics-constrained attack against convolution-based human motion prediction [paper]
Others
[MTAP2023] Transfer the global knowledge for current gaze estimation [paper]
[TCSVT 2021] Energy-based Periodicity Mining with Deep Features for Action Repetition Counting in Unconstrained Videos [paper] [code]
[ROBIO 2019]DBNet: A New Generalized Structure Efficient for Classification [paper] [code]
[-] SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection [paper]
Last update: August 22, 2024
Feel free to contact us at 7858833@bupt.edu.cn, or zsj@bupt.edu.cn.